
When something goes wrong with a dashboard, report, or KPI, most people start at the end. They ask: was this data checked before publishing? Is the report broken? But these question come too late. By the time data hits the end of the pipeline, many opportunities to catch issues have already passed.
In our previous blogs, we discussed why measuring data quality is essential for developing high quality Data Products, and how backwards thinking when developing Data Products enables a quality mindset. This blog builds on our previous blogs, diving deeper into embedding Data Quality throughout the data pipeline. Delays, errors, and inconsistencies are often symptoms of something deeper in the chain. And just like any well-run production proccess, you need to monitor quality as early and often as possible. One final inspection never catches everything.
Three reasons for monitoring data quality throughout the pipeline
Going from singular Data Quality checks to multiple checks throughout the data pipeline is both a technical choice and a cultural shift. It requires more collaboration but ultimately pays off. These are our main three reasons to adopt this approach:
1. It raises awareness and makes Data Quality a team effort
In modern organisations, data flows through complex data landscapes and passes through many hands (source system owners, engineers, analysts). If checks only happen at a singular point, people upstream assume quality is someone else’s job. This creates blind spots and weak accountability.
Embedding DQ checks at multiple points in the pipeline shifts this mindset, as it brings visibility of potential issues to every team involved. It builds awareness, requiring people responsible for source data to be mindful of business needs.
2. It helps trace issues in complex data landscapes
Today’s data pipelines span multiple systems, environments, and teams. Data flows from ERP to cloud warehouses, through transformation scripts and orchestration tools, into dashboards and APIs. But when something breaks, where do you look? A single DQ checkpoint cannot tell you where the issue began. Debugging becomes guesswork.
When multiple DQ checks are embedded in the pipeline, it adds traceability. It becomes easier to pinpoint where a value changed, or a field became null. This makes root cause analysis of your issue much faster. Instead of treating symptoms, problems can be fixed at the source.
3. It builds trust long before the product is delivered.
Trust in data can be lost quickly. Persisting data issues in dashboards will result in users losing confidence. Ultimately, people will rely less on the dashboards, which is problematic as we want data to drive better business decision-making.
By checking Data Quality early, most issues are caught before they reach end users. For example, freshness problems can be flagged right after ingestion and business rules can be validated before data hits reports. When end-users see fewer issues, it will build quiet confidence in data.
How it looks in practice
In our previous blog, we described the ‘Pension Payout’ Data Product developed at Groove, which calculates the monthly pension payments for all employees at Groove. In this simplified example, the data moves from its source system, Snowflake, through a Databricks pipeline to be consolidated into a Data Product.
As the data moves from its source through the data pipeline, Groove has implemented Data Quality checks at every critical step using their Data Quality tool: Soda. We have visualised this below.
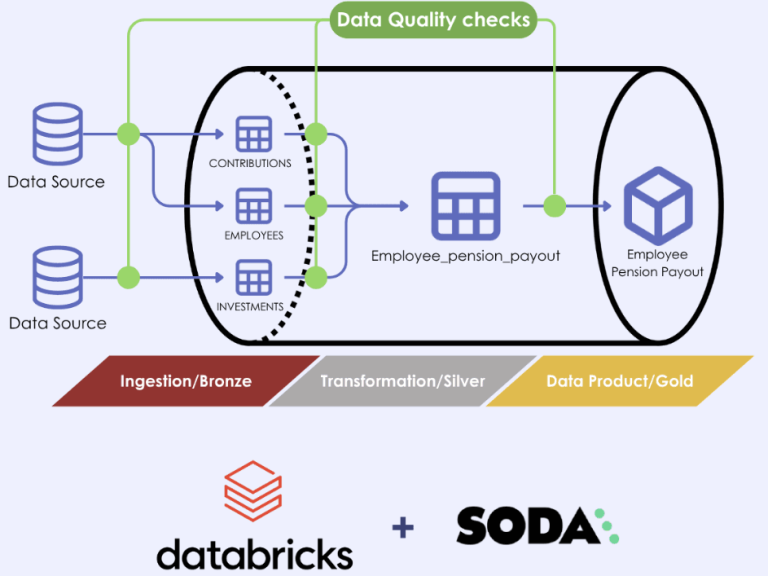
Even for a simple data pipeline, quality checks are deployed at three different stages: pre-ingestion, post-ingestion, and post-transformation. At each stage there are slightly different checks. Some examples:
Post-ingestion check
We will take the simple example of the employee date of birth as a data point. For our Data Product, it is important to have complete and accurate data on employee date of birth to calculate the year of retirement as well as payout eligibility. After the data comes into Databricks, we do the following post-ingestion check:
Date of birth cannot be empty or null.
Or, written in Soda Check Language:
- missing_count(Date_Of_Birth) = 0:
- name: ”Date of Birth should not be null”
- attributes: dimension: [Completeness]
- pipeline_stage: Pre-transformation
This simple Completeness rule ensures we have no missing dates of birth in our Data Product.
Post-transformation check
After transformation of the source tables, we need to check the Data Product for any other rule violations before we make it available for consumption. One of the business rules that the Data Product should comply to is the minimum age of 65 for pension payouts. We can check this easily with the following data quality rule:
Pension Age must be 65 or above.
This too can be written in Soda Check Language:
- failed rows:
- name: ”Pension age should be above 65”
- fail condition: Pension_Age < 65
- attributes:
- dimension: [Validity]
- pipeline_stage: Pre-transformation
These Data Quality checks ensure a robust pipeline and catch issues early. Adding pre-ingestion checks to this process will improve this setup even more. In more complicated pipelines this will be beneficial, as there might be multiple different sources being ingested.
Final thoughts
Just like a regular production line, a data product production line should have quality checks embedded. Never lose sight of the bigger picture: ultimately data is used to achieve business objectives. Whether your focus is compliance or using AI, high-quality data products will help you achieve your goals. And the best way to ensure high-quality data products is by integrating Data Quality throughout your data pipeline.
Clever Republic has worked on multiple successful Data Quality implementations. We are always open to share our thoughts on how to fit Data Quality in your strategy, governance, and technology stacks. Get in touch with us to learn more!