
Organisations spend a lot of time talking about the business-facing layer of data, such as dashboards, reports, and analytics. But underneath all of that sits a quieter layer of data that rarely gets much attention, even though it influences almost everything: Reference Data. It is not the most glamorous part of the data landscape. In fact, it can seem quite technical or administrative at first glance. But once you understand what it is, Reference Data becomes much easier to recognise, and much harder to ignore. Because behind many reporting issues, integration problems, and quality concerns sits the same underlying issue: people and systems are not using the same values to describe the same things. That is exactly where Reference Data comes in.
So, what is Reference Data?
Reference Data is the data used to classify, describe, or constrain other data. In simple terms, it is the set of agreed values that helps systems and people interpret data consistently. That sounds abstract, so let’s make it practical.
Think of values such as:
- country codes like NL, DE, and US
- currency codes like EUR and USD
- order statuses such as New, In Progress, Shipped, or Cancelled
- ticket statuses such as Assigned, Pending, or Resolved
- customer types such as Retail, Wholesale, or Strategic Account
- industry classifications
These are not transactions themselves. They are the controlled values around transactions. They give operational data structure and meaning. If a customer places an order, the order itself is transaction data. But the order status attached to it, the country code used in the address, and the currency code used in the payment are all Reference Data. That distinction matters more than it may seem.
The easiest way to understand it
A simple way to think about the three main data types is this:
- Master Data describes the core business entities, such as customers, products, suppliers, or employees
- Reference Data describes the allowed values used to classify or constrain data, such as country codes, order statuses, or currency codes
- Transaction Data describes business events, such as orders, payments, invoices, or shipments
So if “Customer” is Master Data, then “Customer Type” or “Country Code” may be Reference Data. If “Order” is transaction data, then “Order Status” is Reference Data. Reference Data does not usually get the spotlight, but it quietly shapes how transactions are captured, how Master Data is interpreted, and how analysis is performed.
Why organisations run into trouble without it
Reference Data becomes important the moment the same concept is used in multiple places.
Imagine one system uses these order statuses:
- New
- In Progress
- Closed
And another uses:
- Created
- Active
- Completed
At first, this may not seem like a major issue. After all, the meanings feel roughly similar. But the moment you want to combine data, compare performance, or automate reporting, confusion starts to appear. Are “New” and “Created” exactly the same? Is “Closed” the same as “Completed”, or does one include cancellations and the other not? Does “In Progress” mean work has started, or only that someone has been assigned? This is where ambiguity becomes operational risk. You see the effects in everyday business situations:
- dashboards that do not reconcile
- integrations that need endless mapping logic
- poor quality data entry because users interpret codes differently
- reporting delays because teams need to clarify definitions first
- AI and automation logic that behaves inconsistently because the inputs are not standardised
Reference Data may look like a technical detail, but in practice it is part of how the organisation creates shared meaning.
Reference Data is often simple, but not always
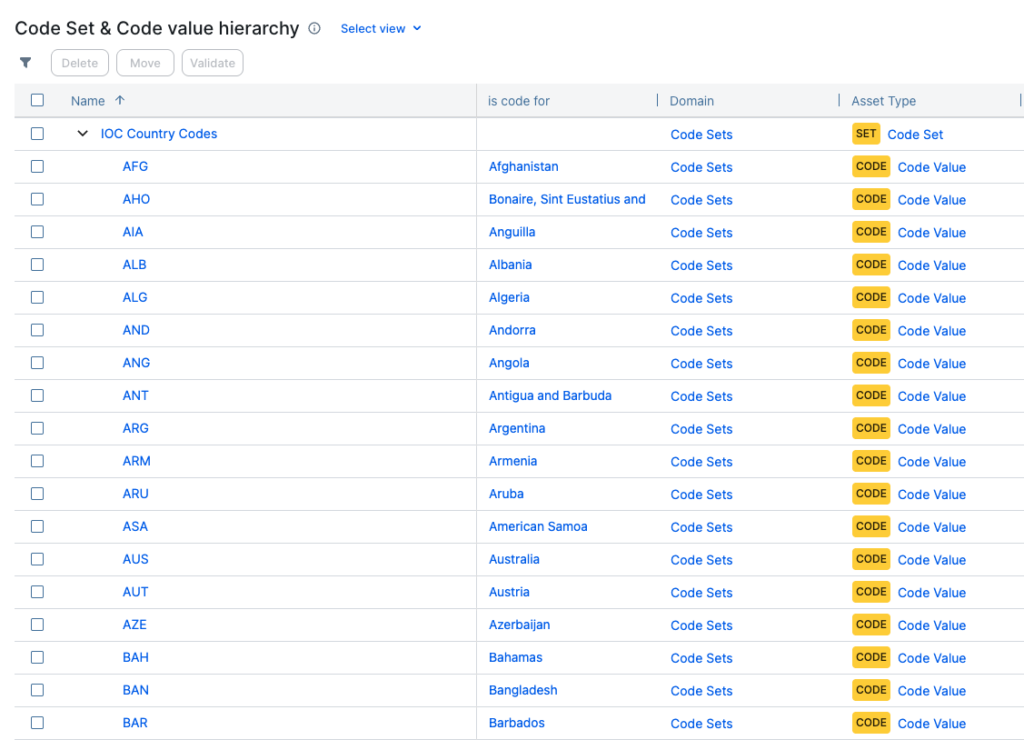
Many people think Reference Data is just a short code and a label. Sometimes it is. A country code list is a good example:
- US = United States of America
- GB = United Kingdom
But Reference Data can also be more complex. Sometimes it includes definitions, not just labels. For example, a helpdesk status code such as “Resolved” may need a formal explanation. That definition matters, especially when the code drives metrics or reporting. Sometimes Reference Data includes mappings between code sets. A US state, for example, can be represented in different standards using different code formats. That requires cross-reference lists to translate one representation into another. Sometimes it is hierarchical. Product classifications, industry classifications, and geographic structures often have parent-child relationships. In those cases, Reference Data behaves more like a taxonomy. So while the concept is straightforward, the implementation can become more involved depending on how much meaning the values need to carry.
Not all Reference Data comes from inside the business
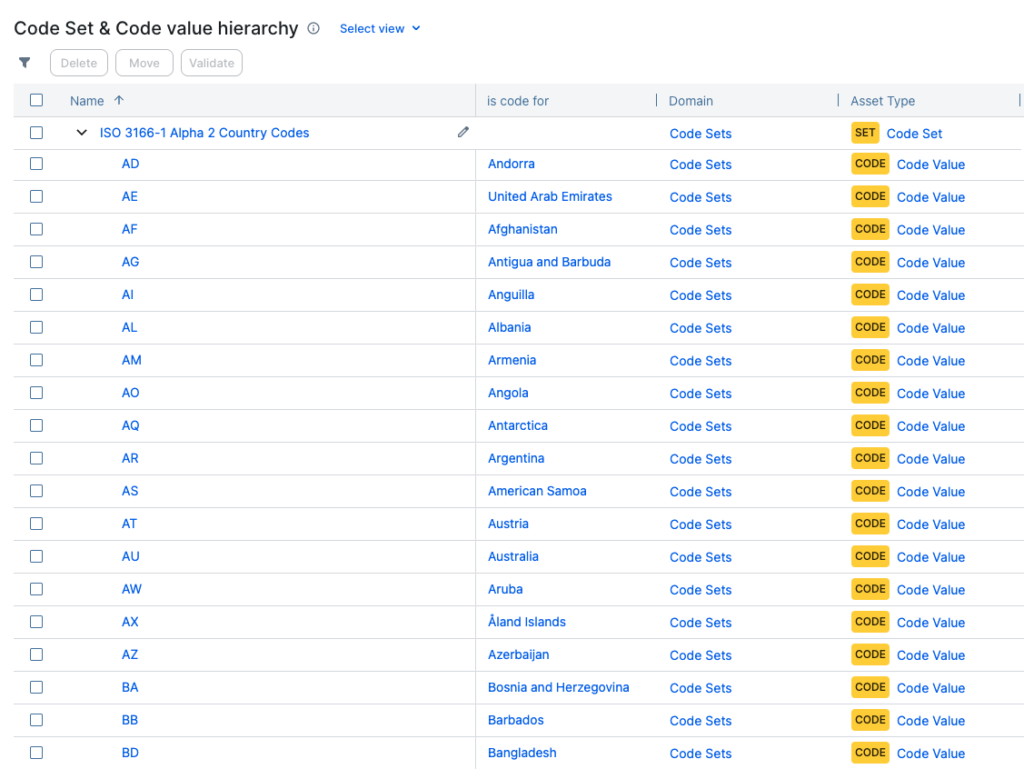
One of the reasons Reference Data management gets tricky is that not all Reference Data is internally owned. Some Reference Data is created and maintained by external organisations, government bodies, or industry standards groups. Think of:
- ISO country codes
- ICD diagnosis codes in healthcare
- foreign exchange rates
- census and geographic classification data
- industry classification standards
This means organisations are often dependent on external changes. Codes may be added, deprecated, or restructured. Those updates then need to be reflected internally. That is why Reference Data should be actively managed rather than simply stored. Good practice usually includes maintaining context around the set itself, such as source, ownership, versioning, and update history, so the organisation understands where the values came from and how current they are.
Why governance matters
Reference Data only creates value when people actually use the same controlled values across systems and processes. That is why Reference Data management goes beyond data modelling and should also be treated as a governance discipline. Reference Data should be shared across the organisation, owned at organisational level rather than by one application or department, monitored for quality, stewarded by accountable roles, and changed only through a controlled process. This is essential, because shared data cannot be changed arbitrarily. If one team decides on its own to rename a status, add a new value, or stop using a code without communicating it, the consequences can spread quickly across reports, integrations, interfaces, and business logic. That is why changes to Reference Data should follow a defined request, review, approval, and communication process.
What good Reference Data management looks like
A strong Reference Data approach does not have to be overly complicated.
In practice, it usually means:
- identifying the Reference Data sets that matter most
- agreeing on standard values and definitions
- assigning stewardship and ownership
- capturing source and version metadata
- managing updates through a clear process
- making the approved values easy to access and reuse
- ensuring systems consume the same controlled values where it matters most
This is what reduces duplicate code lists, lowers integration effort, improves Data Quality, and increases trust in reporting. And perhaps most importantly, it reduces the amount of hidden interpretation in the organisation.
Final thought
Reference Data may seem small, but it plays an outsized role in how consistently an organisation understands and uses data. It is the layer that helps ensure that “Cancelled” means the same thing everywhere. That “GB” is used where one team might otherwise type “UK”. That one classification structure is used where five local versions used to exist. In that sense, Reference Data goes beyond being a technical asset. It is part of the organisation’s operating language. And when that language is inconsistent, every downstream process becomes noisier, harder to integrate, and harder to trust. So while Reference Data may not always be visible, its impact certainly is. Because in the end, many data problems are not caused by missing data at all. They are caused by missing agreement on the values that give data meaning.
If your organisation is running into challenges with inconsistent code values, fragmented classifications, or unclear ownership of shared values, this is often a strong place to start. Bringing more structure and stewardship to Reference Data can create clarity far beyond the data itself. And if you are exploring how to approach that in practice, Clever Republic can help you bring structure, ownership, and consistency to the Reference Data that underpins your data landscape. Check our Data Governance services or get in touch with us!











